1. 저장장치
1) 파일
1. 사용자나 응용 프로그램의 관점에서 : 정보를 저장하고 관리하는 논리적인 단위
2. 컴퓨터 시스템의 관점에서 : 정보를 저장하는 컨테이너, 0과 1의 데이터 덩어리
운영체제의 중요한 역할 중 파일 시스템도 중요하다.
- 파일 생성, 기록, 읽기 등 모든 과정을 통제한다.
- 응용 프로그램은 운영체제 모르게 파일 다루기가 불가능하다.
파일은 어디에 저장되나?
1) 자기장 기반
- 하드디스크, 플로피 디스크
- 자기 테이프
2) 반도체 기반
- SSD
- USB, 플래시 메모리
3) 광학
- CD, DVD
2) 자기장 기반 방식
- 종류에는 자기 테이프, 플로피 디스크, 하드 디스크 등이 있다고 하였다.
- 저장 매체 위에 자기장에 반응하는 물질을 발라두고 헤드를 이용해 특정 위치의 값을 읽어온다.
- 자기장이 변화하면 유도 기전력이 발생한다. 이러한 전류 방향의 변화를 통해 0, 1로 구분한다.
3) 반도체 기반 방식
- SSD, USB 메모리 등이 있다.
- 플래시 메모리에서 수많은 트랜지스터에서 전자를 뺏거나 넣거나를 반복하여 데이터를 읽고, 쓰고, 지우는 과정을 통해 작동한다.
- 전기가 Refresh 되지 않으면 수명은 한정적이다.
- 빠르다. -> 오로지 전자적으로 작동하기에... 또한 튼튼하다.
4) 광학 기반 방식
- CD를 굽는다는 게 진짜다. -> 플라스틱 층을 녹여서 만들기 때문이다.
- 표면에 미세한 홈이 파여 있어 헤드에서 발사된 레이저가 홈에 들어가 반사가 되지 않으면 0, 반사가 되면 1로 인식한다.
5) 디스크
- 플래터 : 정보가 저장되는 매체, 원형 판이다.
- 표면에 자성체가 발려 있어 자기를 이용하여 0과 1의 데이터를 저장할 수 있다.
- 플래터의 표면이 N극을 띠면 0으로 S극을 띠면 1로 인식한다.
- 양면으로 사용하고 2장 이상 구성되며 일정하게 회전한다.
- 헤드 : 플래터를 읽고 쓰기 위한 장치이다. 한 면당 하나의 헤드이다.
- 디스크 제어 모듈
- 프로세서 : 호스트로부터 명령을 받고 해석한다.
- 디스크 캐시 : 1MB에서 몇십 MB 크기의 빠른 반도체 메모리이다.
- 섹터 : 디스트에 정보가 저장되는 최소 단위 (512B or 4096B)
- 트랙 : 플랜터에 정보가 저장되는 하나의 동심원, 여러 개의 섹터들을 포함한다.
- 실린더 : 같은 반지름을 가진 모든 트랙 집합
- 블록 : 운영체제가 파일 데이터를 입출력하는 논리적인 단위이다.

- 디스크 용량 = 실린더 개수 * 실린더 당 트랙 수 * 섹터 수 * 섹터 크기
- 데이터 전송
: 디스크 헤드는 한쪽 방향으로만 회전한다.
: 한 트랙에 여러 섹터에 걸쳐 저장되어 있다.
: 데이터 전송 시간 = 탐색 시간 + 회전 지연 시간 + 전송 시간
- 디스크의 회전 : 각속도 일정 방식
- 플래터는 항상 일정한 속도로 회전하여 바깥쪽 트랙의 속도가 안쪽 트랙의 속도보다 더 빠르다.
- 트랙마다 속도도 다르기에 섹터의 크기도 다르다.
- 가장 바깥쪽에 있는 섹터가 안쪽의 섹터보다 더 큼 (바깥쪽의 속도가 더 빨라서)
- 바깥쪽 트랙으로 갈수록 낭비되는 공간이 생긴다.
- 디스크가 일정한 속도로 회전하기에 구동 장치가 단순하고 조용하게 작동한다는 게 장점이다.
- 보통 HDD는 이 방식을 많이 채택한다.
- 디스크의 회전 : 선속도 일정 방식
- 어느 트랙에서나 단위 시간 당 디스크의 이동 거리가 같다.
- 이를 위해서는 헤드가 안쪽 트랙에 있을 때는 회전 속도를 빠르게, 바깥 트랙에 있을 때는 회전 속도를 느리게 한다.
- 이 또한 바깥쪽 트랙에 더 많은 섹터가 존재한다.
- 한정된 공간에 더 많은 데이터를 넣을 수 있지만
- 모터 제어가 복잡하고 소음이 많다.
- 보통 CD는 이 방식을 많이 채택한다.
이러한 물리적 구조로 인해 조각 모음이 필요하다.
- 파일이 이곳 저곳 흩어지면 디스크의 헤드가 많이 이동해야 하므로 손실이 발생한다.
디스크가 위치를 알아내는 방법 : 주소
- 디스크 물리 주소 : 디스크의 섹터 위치를 나타내는 주소
- CHS 물리 주소 = (cylinder 번호, head 번호, sector 번호)
- 물리 주소의 단위는 섹터이다.
- 운영체제는 논리 블록 주소를 사용한다.
- 응용 프로그램은 파일 내 바이트 주소를 사용한다.
- 주소 변환
- 사용자나 응용 프로그램은 파일 데이터가 바이트 단위로 연속하여 저장된다고 생각한다.
- 운영체제는 파일을 블록 크기로 분할하고 각 블록을 디스크에 분산 저장한다.
- 파일 주소 변환 : 파일 내 바이트 주소 → 논리 블록 주소 → CHS 물리 주소

- 파티션 : 운영체제는 저장 장치를 하나의 연속된 데이터 블록으로 본다고 했다.
-> 하드 디스크가 2개라면 블록이 2개이다.
-> 반대로 하나를 n개로 쪼개는 건? (파티션)
-> 여러 개의 디스크를 하나로 만드는 것도 가능! -> LVM
- 마운트 : 파티션을 디렉터리에 연결하는 행위
- 마운트 포인트 : 다른 파티션을 연결하기 위해 사용되는 디렉터리
- 여러 파티션에 설치된 파일 시스템을 연결하여 전체를 하나의 파일 시스템으로 사용
- 각 파티션에 파일 시스템 설치
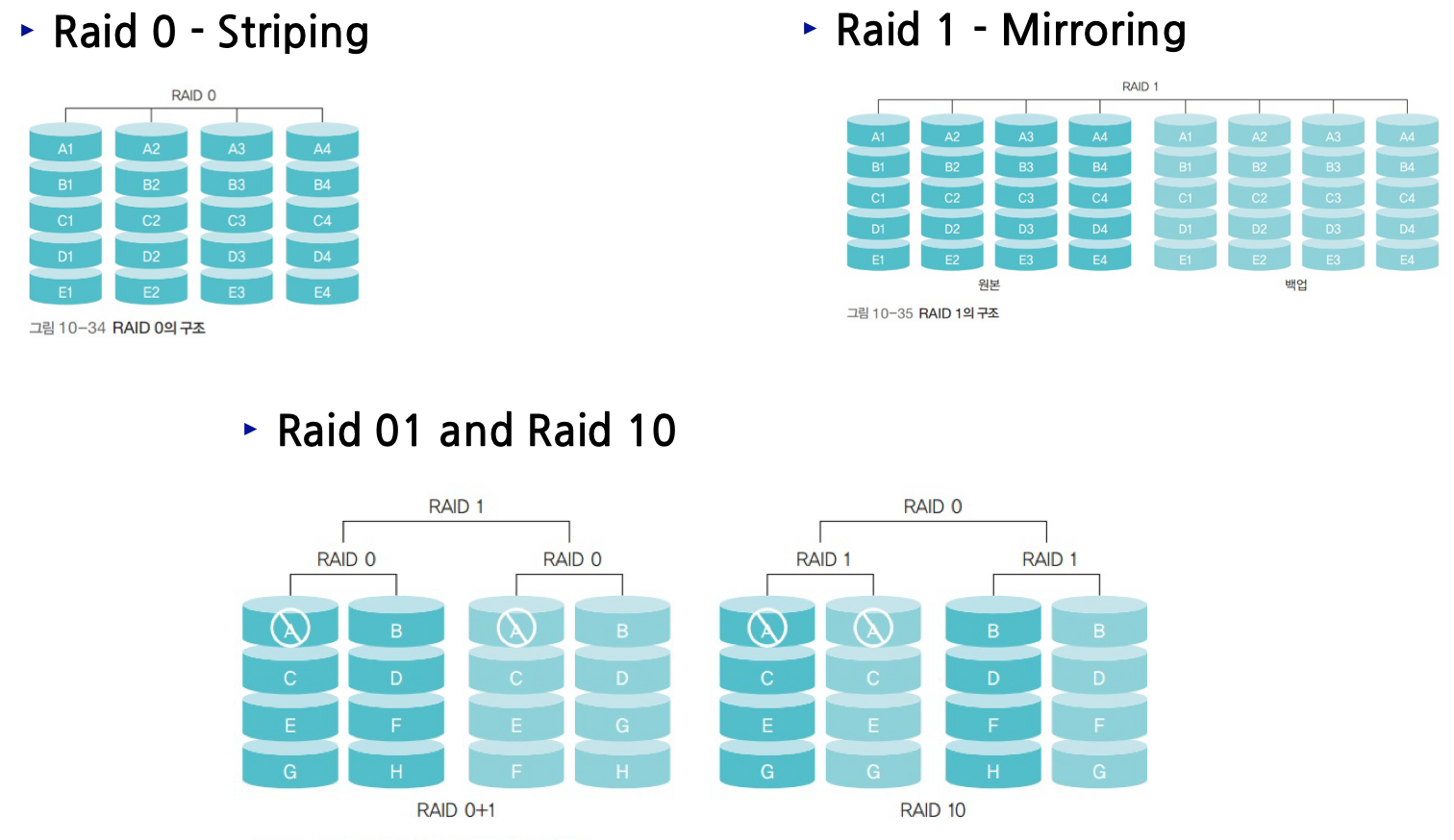
- RAID (Rebundant Array of Independent Disks)
- 여러 개의 디스크를 병렬로 연결하여 사용하는 방법이다.
- 저장 장치를 여러 개 묶어 고용량 / 고성능 디스크 하나와 같은 효과를 얻기 위함이다.
- 하나의 원본 디스크와 같은 크기의 백업 디스크에 같은 내용을 동시에 저장하고, 하나의 디스크가 고장 났을 때 다른 디스크를 사용하여 데이터를 복구
- 저장장치의 고장은 데이터의 손실 -> 레이드는 데이터 신뢰성을 높일 수 있는 방법이다.
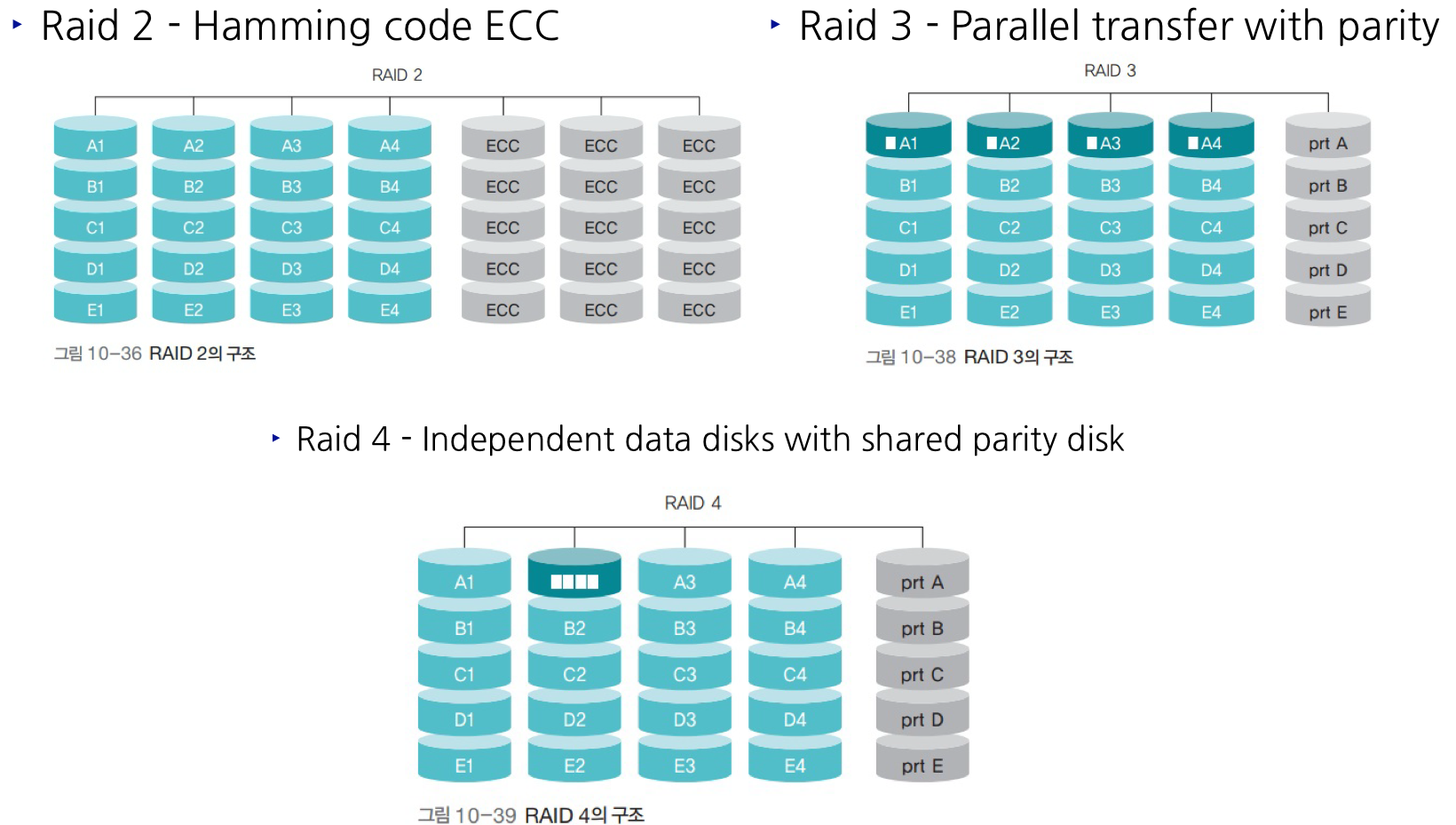
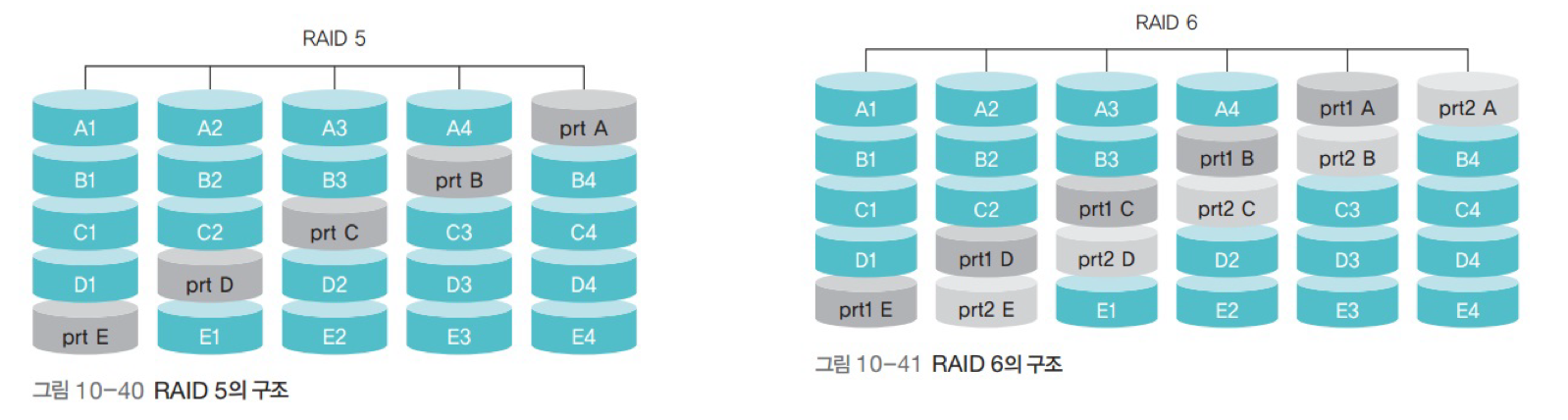
- RAID 구조
I. Raid 0, 1, 10, 01
II. Raid 2, 3, 4
III. Raid 5, 6
- Raid 5 : 패리티 비트를 여러 디스크에 분산하여 보관함으로써 패리티 비트 디스크의 병목 현상을 완화한다.
- Raid 6 : Raid 5에 패리티 비트를 하나 더 추가한 것이다. 디스크 2개의 장애를 복구할 수 있다.
2. 디스크 스케쥴링
1) 효율적으로 주소를 찾아갈 수 없을까?
- 주소로 데이터 위치를 식별하지만 디스크 헤드가 움직이며 식별하는데 시간이 오래 걸린다.
- 디스크 스케쥴링은 탐색 속도를 줄이며 주소를 빠르게 찾아갈 수 있다.
2) 디스크 입출력 성능
1. 탐색 : 디스크 헤드를 목표 실린더로 이동
2. 회전 지연 : 플래터가 회전하여 헤드 밑에 목표 섹터가 도달할 때까지 대기
3. 전송 : 디스크 헤드와 호스트 사이의 전송
4. 오버헤드 : 디스크 프로세서가 호스트에서 명령을 받고 해석하는 등의 부가 과정
1. 탐색
- 디스크 장치 내 모터를 이용하여 디스크 헤드가 현재 실린더에서 목표 실린더로 이동하는 과정이다.
- 탐색 거리 : 이동하는 실린더 개수
- 탐색 시간 : 탐색 거리에 선형적으로 비례, 탐색 거리가 매우 짧은 경우 탐색 시간이 많이 걸린다.
2. 회전 지연
- 탐색 후 플래터가 회전하여 헤드 밑에 목표 섹터가 도달할 때까지 기다리는 시간이다.
- 평균 회전 지연 시간 = 디스크 회전 시간의 절반
- 1회전 시간 = 60s / rpm
3. 전송과 오버헤드
- 디스크 전송 = 외부 전송과 내부 전송으로 나뉜다. 대부분 공개하는 디스크 전송률은 내부 전송 속도이다.
- 내부 전송 시간 = 플래터 표면과 디스크 캐시 사이의 데이터 전송
ex. 트랙 당 섹터가 1000개이고 섹터의 크기가 512B이고 회전 속도가 7200 rpm인 경우
-> 섹터의 크기 = 1000 * 512B = 500KB
-> 1회전 시간 = 60 / 7200 = 약 8.3ms
-> 내부 전송 시간 = 500KB / 8.3ms = 60MB/초
- 외부 전송 시간 = 디스크 캐시와 호스트 컴퓨터 사이에 데이터가 전송되는 시간
- 오버헤드 시간 = 디스크 장치가 호스트로부터 명령을 받고 해석하는 시간
4. 디스크 액세스 및 입출력 시간
- 디스크 액세스 시간
- 목표 섹터에 접근하여 읽거나 쓰기까지 걸리는 시간
- 탐색 시간 + 회전 지연 시간 + 내부 전송 시간
- 입출력 응답 시간
- 호스트나 응용 프로그램 입장에서 디스크 입출력에 걸리는 전체 시간
- 탐색 시간 + 회전 지연 시간 + 전체 전송 시간 + 오버헤드
ex. 디스크 탐색 시간 : 제조 업체에서 명시한 것으로 5ms
디스크의 회전 속도 = 10000rpm => 디스크의 회전 시간 = 6ms => 회전 지연 시간 = 3ms
트랙당 섹터 수 = 1000개 -> 섹터의 크기 = 512B
-> 총 섹터의 크기 = 512KB -> 전송 속도 = 512KB/6ms = 83.3MB/s
-> 섹터 당 속도 = 512KB / 83.3MB/s
-> 디스크 장치와 호스트 사이의 인터페이스 전송 속도 = 100MB/s
-> 디스크 장치의 오버헤드 시간 = 0.1ms
3) 디스크 스케쥴링의 역할
- 트랙의 이동을 최소화하여 탐색 시간을 줄이는 것이 목적
- 큐에 저장된 입출력 요청들의 목표 실린더 위치를 고려하여, 디스크 암이 움직이는 탐색 거리를 최소화하고, 평균 디스크 탐색 시간과 평균 디스크 액세스 시간을 줄여, 디스크 처리율을 극대화한다.
- 디스크 큐 : 도착하는 여러 디스크 입출력 요청을 저장하는 큐
4) 스케쥴링 알고리즘 종류
1. FCFS : 디스크 큐에 도착한 순서대로 요청들을 처리, 기아가 없지만 성능도 없다.
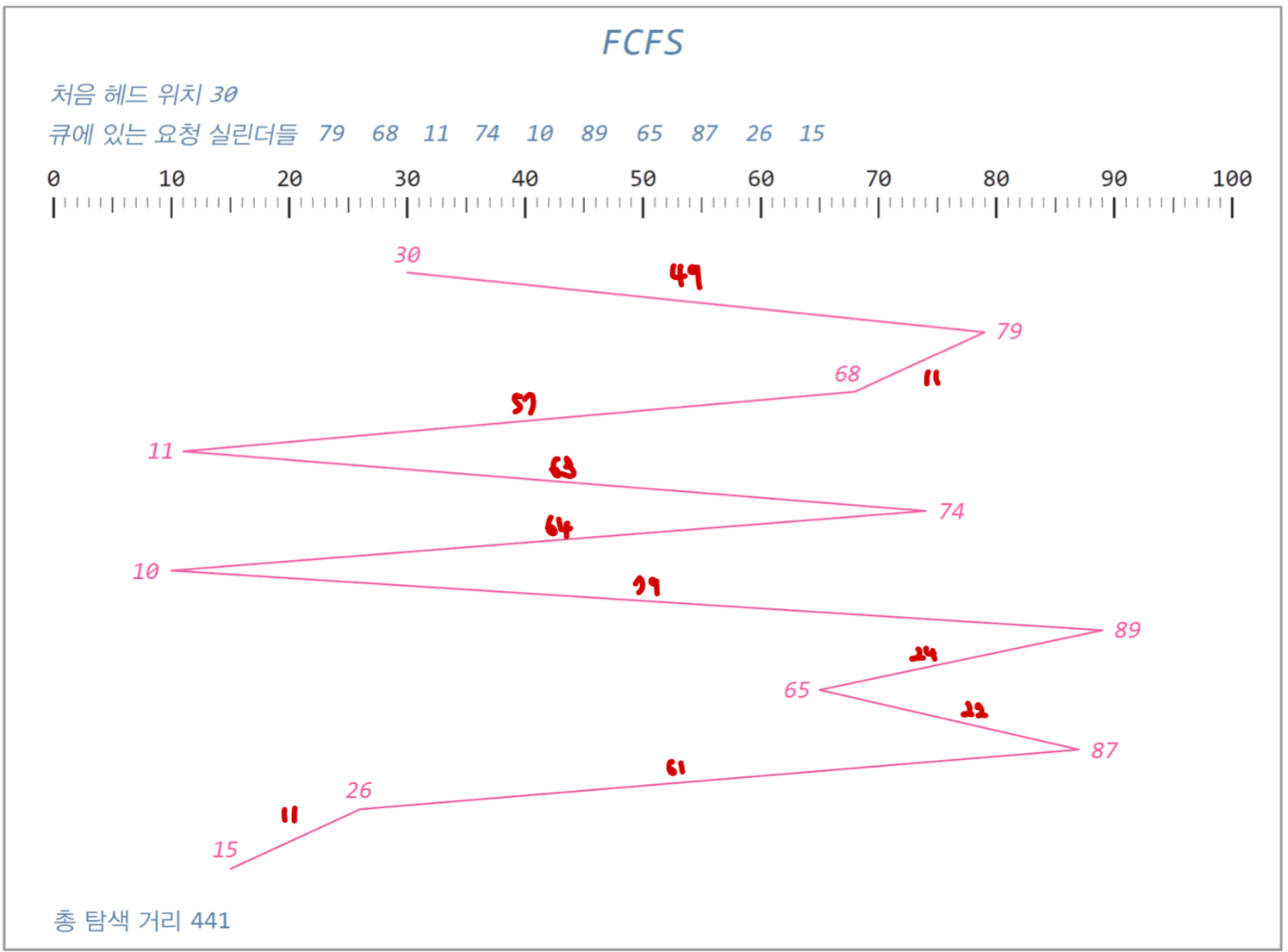
2. SSTF : 현재 디스크 헤드가 있는 실린더 중 가장 가까운 실린더를 선택. 성능은 우수하나 기아 발생 우려
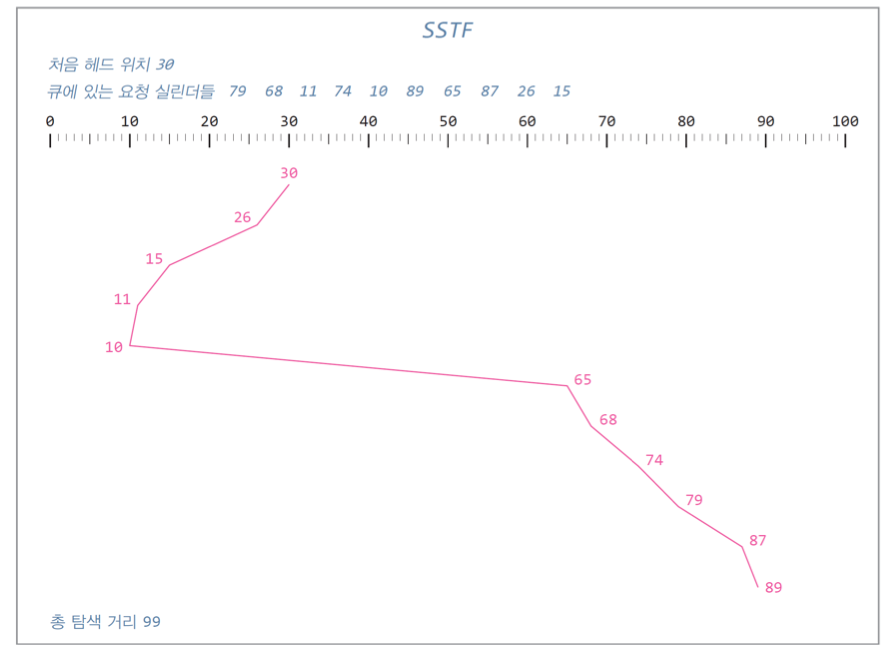
3. SCAN : 가장 바깥 쪽의 실린더의 요청을 끝낸 후 바깥쪽 실린더의 요청이 끝나면 맨 끝의 실린더로 헤드를 이동시키고 나머지 요청 처리
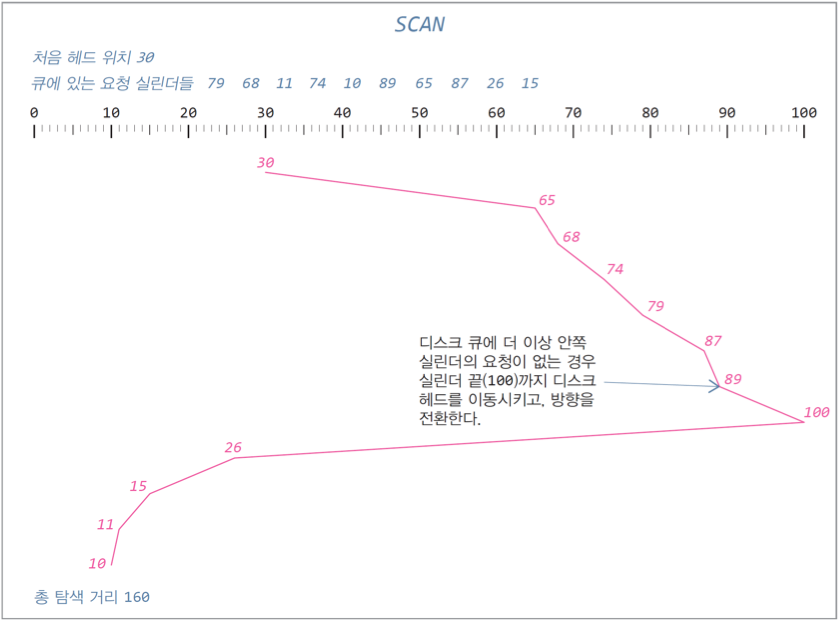
4. LOOK : SCAN 단점을 보완하여 디스크 헤드를 맨 끝으로 보내지 않음

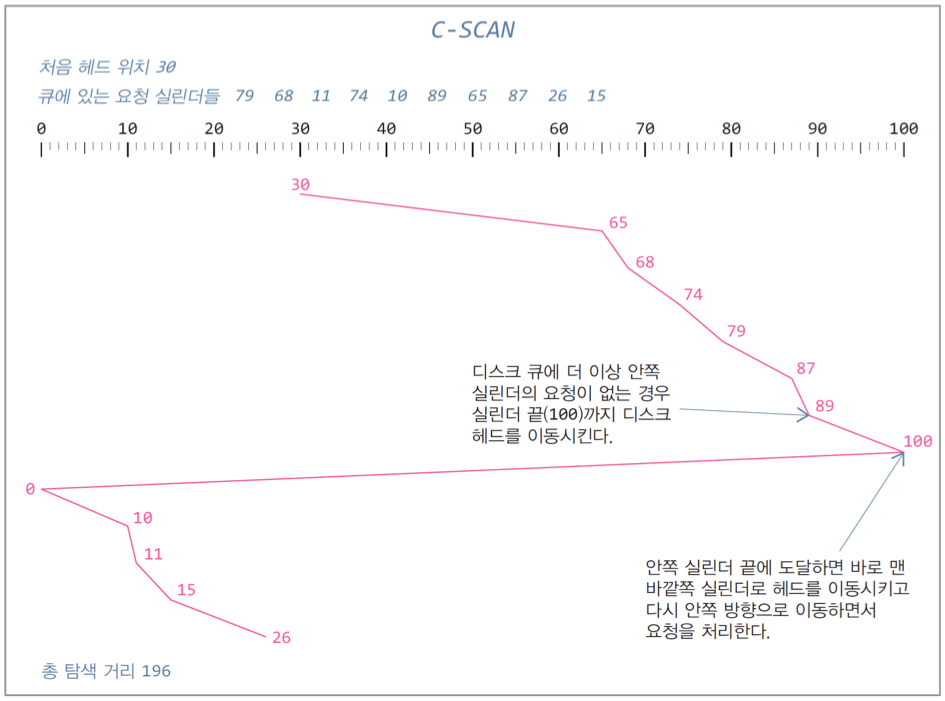
5. C-SCAN : SCAN의 양 쪽 버전, 실린더 헤드를 맨 앞과 맨 끝을 둘 다 오간다.
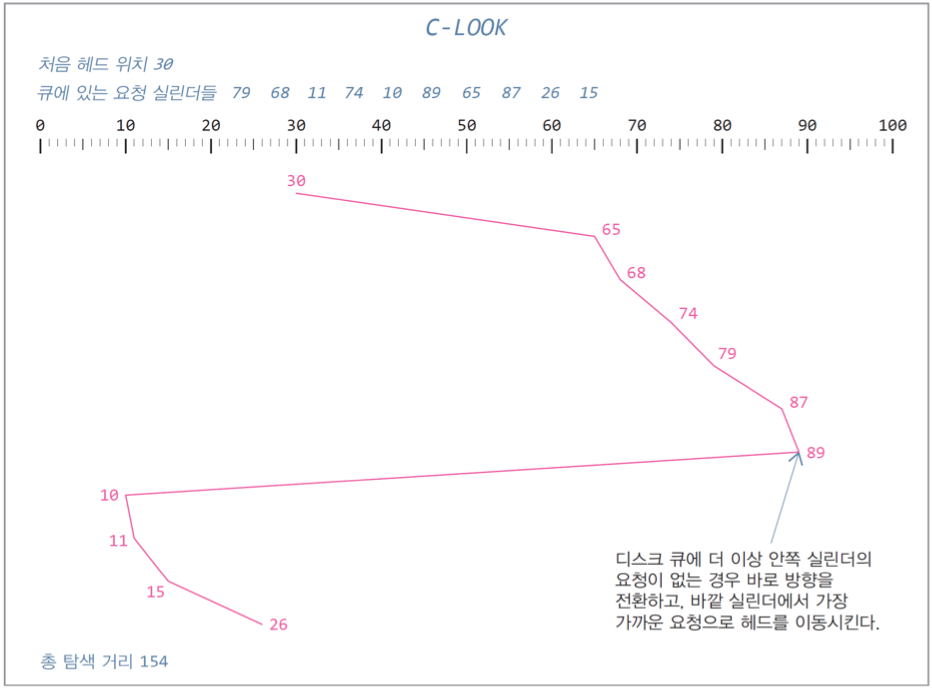
6. C-LOOK : LOOK의 양 쪽 버전
3. SSD
1) FTL (Flash Translation Layer)
- 하드 디스크를 기반으로 하는 운영체제의 파일 시스템은 디스크를 섹터 단위로 인식한다.
- SSD에서는 블록과 페이지로 구성, 저장 단위가 페이지이다.
→ 섹터를 기반으로 하는 기존의 파일 시스템은 SSD를 읽고 쓸 수 없음
- 소프트웨어로 이 문제 해결 → FTL
2) SSD 동작
1. 읽기 : 페이지 단위로 읽어옴
- 한번에 하나의 페이지보다 작은 크기의 데이터를 읽을 수 없음
- 사용자는 운영 체제에게 단 하나의 바이트만 읽기를 요청할 수 있음
2. 쓰기 : 쓰기도 페이지 단위
- 1바이트를 쓰더라도 페이지 하나를 통째로 써야 한다. → 실제 데이터보다 쓰는 양이 더 많아짐
- 어떤 경우든 빈 페이지만 쓸 수 있다.
- 근데 데이터 수정이 일어난다면? → 페이지를 전체로 읽고, 수정하고, 수정된 페이지를 새 페이지에 기록하고, 이 전 페이지를 dirty...
3. 삭제 : 블록 단위
- 페이지는 덮어쓰기가 불가능하기에 dirty, stale 상태는 삭제를 거쳐서 빈 페이지 상태로 전이시킨다.
- 삭제는 페이지 단위로 할 수 없기에 블록 단위로 통째로 삭제한다. → Garbage - Collection
4. 이런 방식은 이유가 있다.
- 플래시 메모리는 쓰기나 지우기 횟수에 비례하여 수명이 마모된다.
- 따라서 여러 페이지로 쓰기를 분산시켜야 한다.
- 웨어 레벨링 (균등 쓰기 분배) : 부하를 골고루 주는 것, 특정 블록에 과도한 쓰기를 막아 수명 단축을 예방한다.
3) 그래서 SSD는...
1. 백업 저장 장치에 적합하지 않다. : 전원이 오래 공급이 되지 않으면 저장된 데이터가 날아간다.
2. 읽기에 능숙하다. : 읽기 작업이 많은 OS 코드나 프로그램에 적합
3. 파일 시스템
1) 파일 시스템
- 저장 매체에 파일을 생성하고 저장하고 읽고 쓰는 운영체제의 기능을 통칭
- 범위
- 파일 시스템의 논리 구조 - 수십만 개의 파일들을 다루기 위한 계층 구조
- 저장소에 파일 시스템 구축 - 파일을 어디에 어떻게 저장할 것인가?
- 커널 내 파일 입출력 구현 - 파일을 읽고 쓰는 등의 기능
- 응용 프로그램을 위한 시스템 호출 제공
- 계층 구조
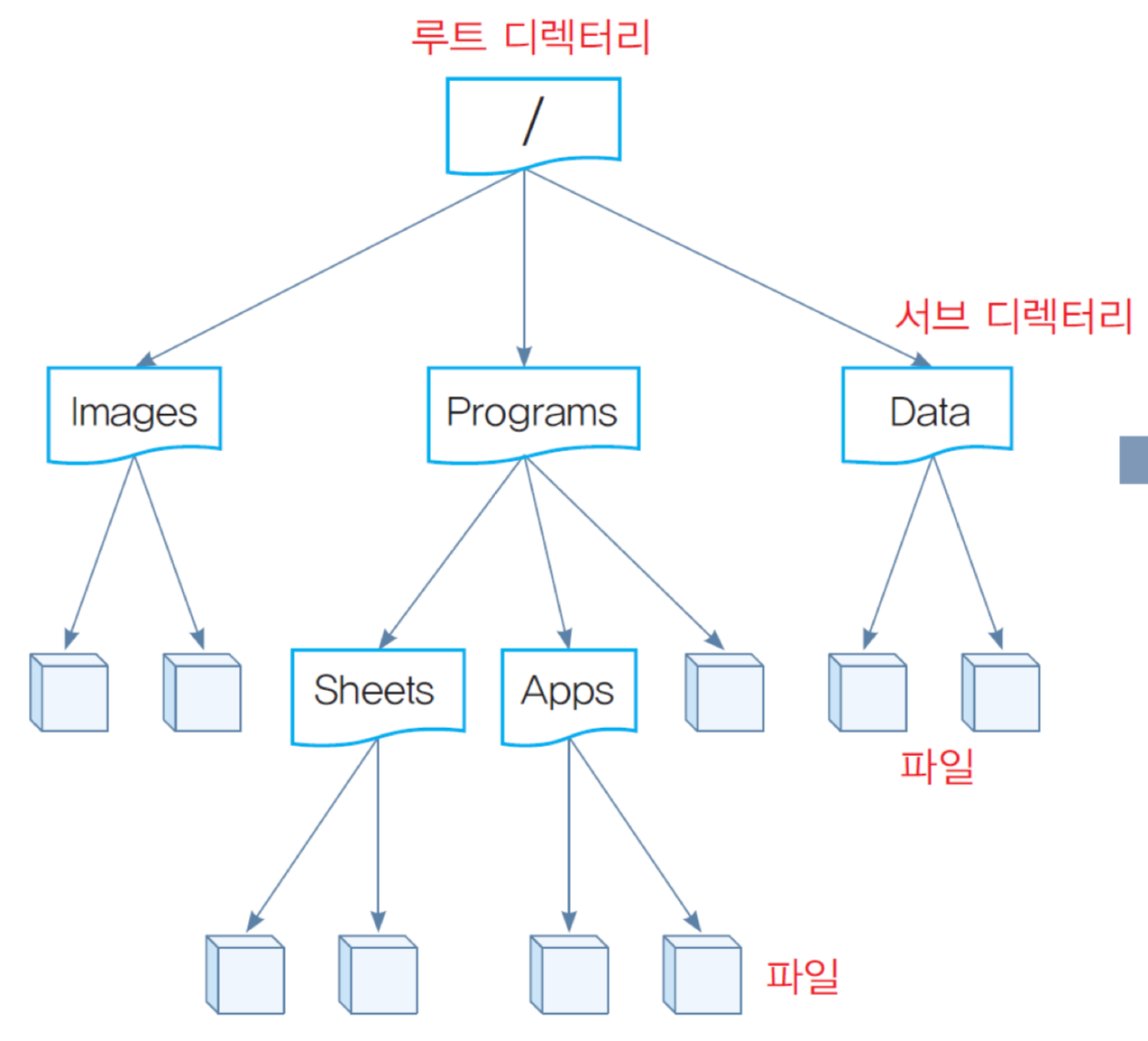
→ 디렉터리도 하나의 파일이다.
2) 디렉터리에 대하여...
1. 논리적 관점 : 여러 파일 혹은 서브 디렉터리를 포함하는 컨테이너
2. 물리적 관점 : 디렉터리도 파일로 구현되고 다루어짐
3) 파일 시스템과 블록
1. 블록은 저장장치에서 사용하는 가장 작은 단위로 한 블록에 주소 하나가 할당
2. 블록은 여러 개의 섹터로 구성되며 블록의 크기는 시스템마다 다르다.
3. 블록 크기를 작게 설정하면 내부 단편화 현상이 줄어들어 저장장치를 효율적으로 쓸 수 있지만, 파일이 여러 블록으로 나뉘어 파일 입출력 속도가 느려진다. → 큰 파일을 많이 사용할 때는 블록 크기를 크게 잡는 것이 좋다.
4) 파일 시스템의 메타 정보
1. 메타 정보란 파일 시스템을 다루기 위한 메타 정보이다.
2. 파일 메타 정보가 저장되는 위치는 파일 시스템의 종류마다 다르다.
3. 파일 시스템 메타 정보
- 파일 시스템 전체 크기와 현재 사용 크기
- 저장 장치에 구축된 파일 시스템의 비어 있는 크기
- 저장 장치에 있는 블록들의 리스트
4. 파일 메타 정보
- 파일 이름, 파일 크기
- 파일이 만들어진 시간, 파일이 수정된 시간, 가장 최근에 액세스 한 시간
- 파일을 만든 사용자, 파일 속성, 파일이 저장된 위치
5) 파일 시스템의 종류
- 범용 : FAT
- xNIX : UFS, ext2, ext3, ext4
- macOS : HFS, APFS
- Windows : NTFS
- 파일 시스템의 이슈
- 디스크에 파일 시스템 포멧 : 디스크 장치에 비어 있는 블록들의 리스트를 어떻게 관리할 것인가
- 파일 블록 할당/ 배치 관리 : 파일 블록들을 디스크의 어느 영역에 분산 배치할 것인가
- 파일 블록 위치 관리 : 파일 블록들이 저장된 디스크 내 위치들을 어떻게 관리할 것인가
1. FAT : 파일 데이터를 블록 단위로 디스크에 분산 저장
- 파일 메타 데이터는 디렉터리에 저장한다.
- 저장된 파일 블록들의 위치는 FAT 테이블에 기록한다.
2. xNIX
- 부트 블록 : 부팅 시 메모리에 적재되어 실행되는 코드, 운영체제를 적재한다.
- 슈퍼 블록 : 파일 시스템 메타 정보 저장
- i-node, i-node 리스트 : 파일 당 한 개씩 필요하다. 0부터 시작하며 리스트의 크기는 포맷 시 결정한다. 포맷 이후 i-node 개수는 고정되어 있다. 0번은 오류 처리를 위해 예약되어 있다.
- 데이터 블록 : 파일과 디렉터리가 저장되는 공간
4. 포맷
1) Disk Formatting
1. 저수준 포맷팅 : 플래터에 트랙과 섹터 구분 정보 기록 (512바이트 포맷, 4KB 포맷)
2. 고수준 포맷팅 : 저수준 포맷된 하드 디스크를 여러 개의 파티션으로 나누고, 각 파티션에 비어있는 파일 시스템을 구축하는 과정
3. 부팅 : 부트 섹터 호출
2) 부팅 과정
1) BIOS 코드 로드 → 2) 부트 로더 코드 → 3) 부트 코드 로드 → 4) 운영체제 이미지 로드
3) MBR (Master Boot Record)
- 디스크의 첫번째 파티션, 첫번째 섹터는 부트 섹터 (512바이트)
- 부터 로더 : 부팅 시 실행되는 프로그램
- 파티션 테이블 : 최대 4개의 파티션 정보 기록
- 매직 번호 : 0xAA55
- 파티션 크기가 2TB로 제한, 부팅 속도가 느리다.
- 부팅 과정
- 전원이 켜지면, CPU는 BIOS 펌웨어 코드 실행
- BIOS 안에 작성된 부트스트랩 코드 실행
- 부트스트랩 코드는 MBR 섹터를 메모리에 적재하고 부트 로더 프로그램 실행
- 부트 로더는 활성 파티션의 부트 섹터를 메모리에 적재하고 실행
- 부트 섹터 코드는 파티션에 설치된 운영체제 커널을 메모리로 적재
- 커널로 제어로 넘긴다. 필요한 프로세스들이 만들어진다.
4) GPT의 부팅 과정
1. 전원이 켜지면 컴퓨터에 장착된 UEFI 펌웨어 실행
2. EFI 변수 읽기 → EFI 변수에는 부팅 수서, 부트 로더의 경로명 등이 담겨있다.
3. 기본 파티션 테이블에서 EFI 시스템 파티션을 찾기
4. UEFI 펌웨어는 EFI 파티션에서 부트 로드 프로그램을 찾아 실행
5. 부트 로더 프로그램은 해당 운영체제 커널을 메모리에 적재
6. 커널 코드로 점프
5. 파일 입출력 연산
1) 파일 입출력
- 운영체제 허락 없이는 디스크에 접근할 수 없다.
- 커널의 파일 시스템은 파일 입출력을 위한 시스템 호출 함수를 제공한다.
- open(), read(), write(), close(), chmod(), create(),mount(), unmount()
- 파일의 경로명으로부터 파일의 i-node를 찾는 과정
'CS 전공 > OS' 카테고리의 다른 글
| [운영체제] 11. Demand Paging (0) | 2024.06.23 |
|---|---|
| [운영체제] 10. 페이징 (0) | 2024.06.23 |
| [운영체제] 9. 메모리 관리 (0) | 2024.06.23 |
| [운영체제] 8. 교착상태 (0) | 2024.06.23 |
| [운영체제] 7. 프로세스와 쓰레드의 동기화 (Synchronization) (0) | 2024.06.23 |